Modelo de Memoria
Introducción
El uso de las memorias es un aspecto fundamental en la programación de GPUs. El uso incorrecto de la jerarquía de memorias disponible en las GPUs puede ocasionar que no consigamos acelerar el algoritmo que estamos implementando de forma paralela, sino que además su tiempo de ejecución sea superior a una implementación secuencial en la CPU. Por ello, la elección del tipo de memoria más adecuada, así como el acceso a los datos en memoria, es realmente importante. El desarrollo de aplicaciones complejas puede requerir el uso de grandes cantidades de memoria, por ello, como ya veremos más adelante, tendremos que utilizar estrategias eficientes para el acceso a los datos. Por mucha capacidad de cómputo que tenga nuestra GPU o CPU, si la velocidad de acceso/escritura de las memorias no es suficiente, toda esta capacidad de cómputo estará desaprovechada.
Jerarquía de memorias
En general, debido a que la memoria con menor latencia esta muy limitada debido a su coste de producción en la mayoría de arquitecturas de computadores, se utilizan organizaciones piramidales donde encontramos memorias de distintos tipos. El objetivo es conseguir el rendimiento de una memoria con una latencia muy baja, al coste de una memoria con una latencia muy alta. Por ello se proponen jerarquías como las que vamos a estudiar a continuación.
Memoria en el Host (CPU)
En la CPU y en la GPU encontramos una jerarquía de memorias bien definida y donde cada memoria tiene un propósito distinto.
A continuación podemos ver un ejemplo típico de la jerarquía de memorias que encontramos en una CPU.
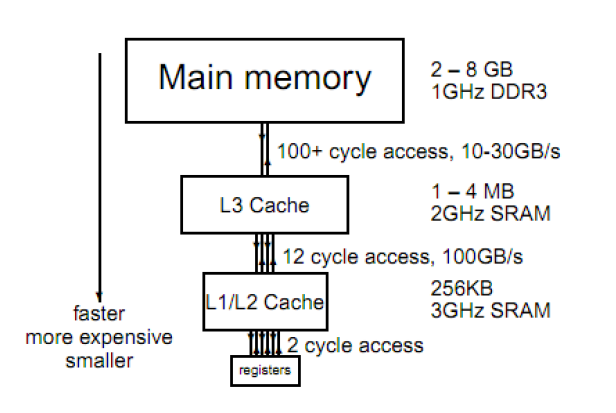
Las memorias se distribuyen en distintos niveles, por un lado encontramos memorias con más capacidad de almacenamiento (Memoria RAM) pero tienen la desventaja de tener un tiempo de acceso superior. Por otro lado, si bajamos en esta jerarquía, encontramos memorias de menor capacidad de almacenamiento, pero mayor velocidad de acceso. En el nivel más bajo, o más cercano al procesador, encontramos los registros. Los registros son un recurso muy limitado pero con una latencia muy baja. En los niveles intermedios, encontramos otro tipo de memorias con una capacidad de almacenamiento media, y con un tiempo de acceso también medio. Este tipo de memorias es muy útil para implementar lo que se conoce en arquitectura de computadores, como memoria caché. En este tipo de memorias se almacena un subconjunto de datos almacenados en la memoria principal. En concreto, el sistema operativo intentará almacenar los datos que más se estime que se vayan a reutilizar (mayor frecuencia) a lo largo de la ejecución de nuestro programa. La jerarquía de memoria va a permitir aumentar el rendimiento gracias a la explotación del principio de localidad. Encontramos dos tipos de principios de localidad:
Localidad temporal: un dato que ha sido utilizado recientemente es probable que se utilice de nuevo a corto plazo
Localidad espacial: es probable usar los datos adyacentes a los usados recientemente, por ello se usan caches para guardar varios datos en una línea del tamaño del bus de acceso a memoria.
Esta jerarquía de memoria junto con el principio de localidad utilizado de forma correcta, permite sacar el máximo rendimiento a nuestros programas en la CPU, reduciendo el tiempo consumido en acceder a la memoria del ordenador.
Memoria en el Device (GPU)
La GPU, y en concreto una GPU compatible con CUDA, dispone de una jerarquía de memorias ligeramente distinta a la que acabamos de ver, la mayoría de estas diferencias se deben a la capacidad de computación paralela de las mismas.
Además, la jerarquía de memorias de la GPU dispone de una interfaz para comunicarse con la memoria principal de la CPU, ya que la GPU necesita de una CPU para su funcionamiento. La CPU es la encargada de coordinar la copia de datos a las memorias de la GPU, así como la ejecución de código sobre sus procesadores. A partir de ahora, cuando hablemos de memoria en la GPU, nos referiremos a esta usando el término Device memory. La device memory esta referida a la memoria de una GPU en concreto, y la GPU dispone de un controlador de memoria dedicado encargado de gestionar todas las transferencias entre el Host y el device (CPU <--> GPU). La memoria device es la memoria de mayor capacidad en la GPU, y normalmente nos referimos a ella como la memoria GDDR. Por ejemplo, la tarjeta gráfica de NVIDIA GTX480 dispone de 1.5 GB de memoria GDDR3. Por lo tanto la capacidad de la device memory de esta tarjeta gráfica es de 1.5 GB. Si consultamos la capacidad de otras tarjetas más modernas, por ejemplo, la NVIDIA GTX1080, esta tarjeta gráfica dispone de 8 GB de memoria GDDR5X. Esta memoria no solo dispone de más capacidad, sino que su latencia es menor.
La device memory puede ser utilizada en CUDA de distintas maneras, de forma que según el tipo de reserva que hagamos, la memoria tendrá un uso diferente y por lo tanto a su vez también un rendimiento distinto. A continuación vamos a ver y analizar con detalle las características de cada una de las distintas formas en que podemos reservar memoria en la device memory de una GPU compatible con CUDA:
Memoria global
La memoria global es la memoria de mayor tamaño que encontramos en la GPU. A su vez, es la memoria con mayor latencia. Debido a su capacidad, esta memoria se utiliza normalmente como contenedor cuando copiamos datos entre el Host (CPU) y el Device (GPU). Posteriormente los datos pueden ser copiados a otras memorias más eficientes para optimizar el acceso a los datos, por ejemplo, a través del uso de la memoria compartida o registros.
La memoria global es compartida por todos los Streaming Multiprocessors de la GPU, por lo que todos los hilos podrán acceder al mismo espacio de direcciones de forma simultánea. El acceso a esta memoria tiene una elevada latencia, por lo que hay que minimizar su uso desde los kernels. Para intentar acelerar en la medida de lo posible el acceso a esta memoria, es muy recomendable seguir un patrón de acceso coalescente, de forma que hilos consecutivos accederán a posiciones contiguas en memoria. De esta forma, con la lectura de una línea de memoria, podremos proporcionar datos para múltiples hilos de ejecución.
A continuación vamos a ver un ejemplo de como reservar dinámicamente memoria global de la GPU en nuestros programas:
int *dev_a = 0;
// Reserva memoria en la GPU para un vector de enteros.
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
En el ejemplo de arriba, hemos utilizado la instrucción CUDA cudaMalloc para reservar en la memoria GPU espacio para un vector de enteros de tamaño size. Como primer parámetro recibe la dirección de memoria del puntero que hemos declarado para manejar un vector de enteros en la memoria global de la GPU. Como segundo parámetro especificamos el tamaño en bytes que queremos reservar. En este caso utilizaremos la función de C/C++ sizeof(tipo de datos) para calcular el número de bytes que ocupa cada elemento del tipo de datos que vamos a almacenar, en nuestro caso un valor entero ocupa internamente 4 bytes. El puntero dev_a nos servirá para acceder a la memoria declarada desde nuestros kernels CUDA. Una buena práctica es poner delante del nombre de estas variables algo que nos permita identificar rápidamente si la memoria esta reservada en la GPU o la CPU, por ejemplo: dev_nombrevariable o d_nombrevariable. Este puntero hace referencia a una dirección de memoria en la GPU, este espacio de direccionamiento es distinto al espacio de direccionamiento de la CPU. Por lo tanto, si intentamos referenciar una dirección de memoria de la GPU desde la CPU, obtendremos un error, ya que esa memoria esta protegida y solo puede ser accedida desde la GPU (Kernels).
La reserva de memoria en la GPU se lleva a cabo desde la CPU. El proceso de reservar memoria es un proceso costoso, el cual además fuerza a sincronizar las operaciones pendientes en la GPU, de forma que eliminaría cualquier nivel de concurrencia o solapamiento que estuviesemos intentando conseguir entre la CPU y la GPU. Por ello, la reserva o liberación de memoria global se lleva a cabo al principio y al final de nuestros programas respectivamente, evitando reservar memoria en mitad de nuestro código, ya que esto puede causar un gran impacto en el rendimiento de nuestra aplicación. Ya veremos que algo similar ocurre con las transferencias de memoria.
Al igual que en C/C++, la memoria dinámica tiene que ser desalojada de forma manual. De esta forma la API de CUDA también dispone del siguiente comando para liberar la memoria reservada una vez terminos de utilizarla. Al final de nuestro programa liberaremos toda la memoria de la GPU que hayamos reservado de forma dinámica utilizando la siguiente isntrucción:
cudaError_t cudaFree(void *devPtr);
Consultando cantidad memoria global disponible
Utilizando la API de programación CUDA es posible en tiempo de ejecución consultar la cantidad de memoria global disponible, de esta forma podremos consultar en nuestros programas si tenemos suficiente memoria antes de proceder a reservarla. Si intentamos reservar más memoria global de la disponible en nuestra tarjeta gráfica, la llamada a la función cudaMalloc nos devolverá un código de error.
Para obtener la cantidad de memoria llamamos a la función cudaGetDeviceProperties(). Esta función nos rellenará una estructura de datos propia de CUDA con información sobre la GPU instalada en nuestro sistema. Para consultar la memoria disponible accedemos al campo cudaDeviceProp.totalGlobalMem. Este campo contiene la cantidad de memoria global disponible en bytes.
size_t totalGlobalMemory; // tamaño total de la memoria global en bytes
Transferencia de datos entre memoria CPU y memoria global GPU
La memoria global en la GPU suele ser el punto de entrada para alojar los datos que va a utilizar nustra aplicación en tiempo de ejecución. Por ello, una vez hemos reservado memoria global en la GPU, podemos transferir datos en ambas direcciones CPU <-> GPU utilizando el comando cudaMemcpy() de la API de CUDA. La función cudaMemcpy() recibe cuatro parámetros de entrada. El primer parámetro es un puntero a la dirección en memoria GPU donde vamos a copiar los datos. El segundo parámetro es un puntero a la dirección de memoria CPU dond se encuentran los datos que vamos a copiar a la memoria GPU. El tercer parámetro especifica el número de bytes a copiar desde la dirección origen a la dirección destino. En este caso, si conocemos el tipo de datos que vamos a utilizar podemos ayudarnos de la función sizeof(tipo de dato) para obtener el tamaño del tipo de dato que vamos a copiar. Finalmente, el cuarto parámetro especifica la dirección en la que vamos a llevar a cabo la transferencia de datos. En la API de CUDA encontramos las siguientes opciones:
cudaMemcpyHostToDevice: transferencia de datos de memoria CPU a memoria GPU.cudaMemcpyDeviceToHost: transferencia de datos de memoria GPU a memoria CPU.cudaMemcpyDeviceToDevice: transferencia de datos entre dos direcciones de memoria GPU.
El flujo habitual de transferencia de datos entre CPU y GPU se realiza al principio y al final de nuestra aplicación, evitando así transferencias de datos durante la ejecución de nuestra aplicación. Por lo tanto, copiaremos datos de memoria CPU a GPU al princpio de nuestra aplicación, lanzaremos una serie de trabajos (kernels) en la GPU, y finalmente copiaremos los resultados de vuelta a la CPU para su visualización o escritura en disco. Este es el flujo ideal en cualquier aplicación que desarrollemos en la GPU. De hecho, si los resultados computados en los kernels CUDA tienen como único objetivo su visualización, no sería necesario copiar esta información de vuelta a la CPU, se podrían visualizar directamente utilizando por ejemplo el lenguaje OpenGL o DirectX, lenguajes de programción gráfica. Ambos lenguages pueden interoperar con direcciones de memoria reservadas utilizando la API de CUDA, de forma que no requiere copiar de vuelta los datos a la CPU y copiarlos de nuevo a la memoria de la GPU utilizando la API de OpenGL y/o DirectX. CUDA ofrece una serie de mecanismos de comunicación con OpenGL y DirectX, permitiendo al desarrollador bloquear esa porción de memoria hasta que se ha visualizado de forma gráfica.
A continuación podemos ver el ejemplo típico de la suma de vectores. Inicialmente copiamos los vectores almacenados en memoria CPU a memoria GPU. Posteriormente ejecutamos el kernel para computar la suma de ambos, y finalmente copiamos los resultados de vuelta a la memoria de la CPU para su visualización.
cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
Es importante saber que la ejecución de la instrucción cudaMemcpy() es síncrona. Lo que significa que fuerza a la CPU a esperar a que la GPU finalice todas las tareas que tenga pendientes. Ya veremos que en la API de CUDA existen dos tipos de instrucciones, las síncronas y las asíncronas. Por defecto las instrucciones de copia entre memorias son síncronas y por ejemplo la invocación de kernels es asíncrona. Normalmente existen variaciones de la mayoría de funciones que permiten su ejecución en ambas modalidades, síncronas y no síncronas. En el caso de la función cudaMemcpy() encontramos la variante cudaMemcpyAsync. Esta instrucción no fuerza a la sincronización de la CPU y la GPU, por lo que es útil para permitir la ejecución solapada de kernels, transferencias entre memorias y trabajo en la CPU. El desarrollador será el encargado de asegurar que no existen dependencias entre las instrucciones asíncronas que vamos a utilizar. La utilización de instrucciones asíncronas, junto con la utilización de cudaStreams nos permitirá obtener un mayor rendimiento en nuestra aplicación en aquellos casos en que ciertas tareas se puedan solapar en el tiempo.
Reserva estática de memoria global
También es posible reservar de forma estática memoria global. Para ello podemos utilizar el modificador __device__ delante la variable que declaremos. De esta forma le estamos indicando al compilador de CUDA que esa variable se va a alojar en memoria global de la GPU. Cuando nuestro programa se ejecute alojará esa memoria de forma automática y no tendremos que encargarnos de liberar la memoria de forma manual, ya que el driver de CUDA lo hará de forma automática.
Podemos copiar información a este espacio de memoria declarado de forma estática utilizando las siguientes instrucciones:
cudaError_t cudaMemcpyToSymbol(
char *symbol,
const void *src,
size_t count,
size_t offset = 0,
enum cudaMemcpyKind kind = cudaMemcpyHostToDevice
);
cudaError_t cudaMemcpyFromSymbol(
void *dst,
char *symbol,
size_t count,
size_t offset = 0,
enum cudaMemcpyKind kind = cudaMemcpyDeviceToHost
);
Mediante estas dos instrucciones podemos copiar y leer, respectivamente, información de estas variables alojadas de forma estática en la memoria de la GPU.
Memoria local
La memoria local es una memoria de tipo stack a nivel de hilo de ejecucion. Cuando un hilo que se ejecuta dentro de un SM ha ocupado el número máximo de registros disponibles en ese SM, se produce lo que se conoce como register spilling, y las variables declaradas que ya no caben en los registros pasan a almacenarse en memoria local. En las primeras version de CUDA la memoria local se implementaba únicamente en memoria global, por lo que cuando esto ocurría, el rendimiento de la aplicación se degradaba de forma considerable. A partir de la arquitectura Fermi, este problema se mejora con la introducción de memorias caches L1 y L2. De forma que estas variables pasan a almacenarse en estas memorias. Estas memorias cache L1 y L2 son bastante más rápidas que la memoria global, reduciendo así el impacto en el rendimiento de nuestra aplicación. Es posible analizar detalladamente el uso de registros y memoria local de nuestra aplicación. Si especificamos el modificador -Xptxas –v,abi=no en la compilación de nuestro programa, el compilador imprimirá información sobre la utilización de los registros, así como la memoria local para cada uno de los kernels de nuestro programa. También podemos solicitar información sobre la ocupación de la memoria local en tiempo de ejecución mediante el siguiente comando:
cuFuncGetAttribute(CU_FUNC_ATTRIBUTE_LOCAL_SIZE_BYTES).
Con lo descrito anteriormente podemos ver que la gestión de la memoria local es automática, aunque tendremos que tomar precauciones respecto a su uso, ya que esto puede ocasionar pérdidas de rendimiento. Por otro lado, el uso de la memoria local nos permite llevar a cabo transacciones en memoria de forma coalescente, evitando este problema cuando el acceso a memoria global no se produce de forma coalescente.
Registros
La memoria más cercana a los procesadores, de más bajo nivel y con menor latencia que encontramos en la GPU son los registros. En una GPU compatible con CUDA cada SM tiene miles de registros que se reparten entre todos los hilos de ejecución de nuestros kernels. Por ejemplo, en una GPU de arquitectura Kepler (SM 3.0), cada SM contiene 65536 registros o 256 KB de memoria para este propósito.
Podemos saber el número de registros que cada kernel utiliza en tiempo de compilación añadiendo el siguiente modificar durante la compilación de nuestro código: --ptxas-options -–verbose.
El número de registros utilizado por un kernel afecta al número de hilos que pueden ejecutarse en un multiprocesador de forma paralela. Ajustando el número de registros que dispone cada hilo de ejecución podremos ajustar de forma más específica el rendmiento de ciertos kernels de nuestro código. El número máximo de registros utilizados por cada hilo se puede especificar en tiempo de compilación con el modificador --ptxas-options --maxregcount N donde N es el número máximo de registros por hilo.
Memoria de constantes
La memoria de constantes esta optimizada para accesos de solo lectura de forma simultánea por múltiples hilos en paralelo. La memoria de constantes reside en la memoria device aunque el acceso a la misma se lleva a cabo con instrucciones distintas permitiendo su uso como una memoria cache especializada. Los desarrolladores tienen a su disposición 64 KB que pueden ser utilizados para almacenar constantes. Para declarar en nuestro código una variable como constante utilizaremos el siguiente modificador delante de las variables declaradas: __constant__.
La memoria constante puede ser modificada mediante la utilización de instrucciones CUDA de copia de datos entre memorias o accediendo el puntero a memoria GPU desde un kernel. No se debe acceder a memoria de constantes en el mismo kernel que utilizamos para acceder a esta parte de la memoria , ya que CUDA no mantiene coherencia de la misma en tiempo de ejecución.
Para copiar datos a memoria de constante utilizaremos las siguientes instrucciones:
cudaMemcpyToSymbol() \\ Nos permite copiar datos a memoria de constantes
cudaMemcpyFromSymbol() \\ Nos permite leer el contenido de una variable alojada en memoria de constantes
También podemos leer/modificar la memoria de constantes accediendo al puntero que contiene la dirección de memoria GPU donde se almacena dicha información. Para obtener la dirección de memoria se tiene que utilizar el comando:
cudaError_t cudaGetSymbolAddress( void **d_ptr, char *nombre_variable_constant );
También podemos obtener en tiempo de ejecución la cantidad de memoria de constantes utilizada mediante el comando cuFuncGetAttribute(CU_FUNC_ATTRIBUTE_CONSTANT_SIZE_BYTES).
Memoria de texturas
En CUDA, cuando trabajamos con la memoria de textura, lo haremos a través de dos objetos o entidades distintas. Por un lado usaremos el tipo de datos cudaArray para llevar a cabo la reserva de memoria en la GPU. Por otro lado, utilizaremos un objeto denominado 'referencia a textura', del inglés 'texture reference', el cual contiene información sobre el tipo de información almacenada en la memoria de texturas, como se debe llevar a cabo el acceso a memoria de texturas, así como el acceso a la misma. Cuando utilizamos un cudaArray para acceder a la memoria de texturas, la GPU internamente utiliza una memoria cache de solo lectura, la cual proporciona un mayor rendimiento, especialmente cuando no se producen accesos coalescentes. La memoria de texturas es recomendable para estos casos, donde el acceso a memoria global no se produce de forma coalescente. La memoria de textura es especialmente cuando tenemos datos de solo lectura sobre los que vamos a realizar operaciones que requieren accesos no coalescentes a memoria, por ejemplo, aplicar distintos filtros o convoluciones 2D sobre una imagen.
También cabe destacar que la memoria de texturas se puede configurar para que el acceso a los datos se haga utilizando interpolación lineal y/o normalización de los datos de forma automática. Estas operaciones de normalización o de acceso a los datos utilizando interpolación bilineal tienen un coste computacional muy bajo gracias a la utilización de la memoria de texturas.
Memoria compartida
La memoria compartida, del inglés 'Shared memory' es una memoria un tanto especial y diferente respecto a las que hemos visto hasta ahora. La memoria compartida se encuentra dentro de cada SM, y tiene una latencia muy baja. Su principal propósito es el intercambio de información entre hilos dentro de un mismo bloque que se ejecutan en un SM. Aunque esta memoria es realmente rápida, su rendimiento es todavía alrededor de 10 veces más lento que los registros, pero mucho más rápida que la memoria global. Por ello, la utilización de forma combinada de todas las memorias disponibles es la clave para obtener el máximo rendimiento en nuestra aplicación.
La memoria compartida es un recurso esencial que se utiliza para copiar datos que se van a reutilizar dentro de nuestros kernels, por lo que copiaremos la información desde memoria global a memoria compartida y los posteriores accesos se llevarán a cabo a través de la memoria compartida, reduciendo así la latencia causada por un acceso repetido a la memoria global.
La memoria compartida es manejada por los desarrolladores, por lo que la reserva de esta memoria, así como la copia de datos a la misma es tarea del desarrollador. La memoria compartida se puede ver como una memoria caché manejada de forma manual por el desarrollador. Para la utilización de la memoria compartida en nuestros kernel deberemos llevar a cabo los siguientes pasos:
Declarar la cantidad de memoria compartida a utilizar por nuestro kernel.
Cargar los datos en memoria compartida, normalmente los datos se leen desde memoria global y se almacenen en memoria compartida. Para asegurarnos que todos los hilos han terminado de copiar su porción de los datos se ejecuta una instrucción de sincronización a nivel de bloque de hilos: __syncthreads().
A continuación llevamos a cabo el procesamiento requerido, cálculos, leyendo los datos almacenados en la memoria compartida.
Finalmente deberemos sincronizar __synchtreads() de nuevo los hilos antes de empezar a escribir en memoria para asegurarnos que todos los hilos del bloque han terminado de llevar a cabo los cálculos requeridos por nuestro kernel. Tras esto, escribiremos los resultados en memoria global para poder acceder posteriormente a ellos, ya que la memoria compartida no será accesible tras finalizar la ejecución de nuestro kernel.
Podemos declarar memoria compartida en nuestro kernel de dos formas distintas. Utilizando el modificador __shared__ delante de las variables que definamos en nuestro kernel. Podemos ver un ejemplo a continuación:
/* CUDA Kernel 2D shared memory */
__global__ void medianFilter2D_sm(unsigned char *d_output, unsigned char *d_input)
{
// declaración de memoria compartida para almacenar una porción de una imagen
__shared__ unsigned char d_input_sm[(BLOCK_H+2)*(BLOCK_W+2)];
...
}
La otra forma de declarar memoria compartida en nuestro kernel consiste en declarar variables sin tamaño y especificar el tamaño de memoria compartida que necesitamos en nuestro kernel a la hora de invocarlo. Ejemplo:
/* CUDA Kernel 2D shared memory */
__global__ void medianFilter2D_sm(unsigned char *d_output, unsigned char *d_input)
{
extern __shared__ unsigned char d_input_sm[];
...
}
...
// llamando al kernel
medianFilter2D_sm<<< gridSize, blockSize, (BLOCK_H+2)*(BLOCK_W+2)*sizeof(char) >>>( ... );
Como podemos ver, el tamaño de la memoria compartida se especifica cuando invocamos el kernel, de forma que cada bloque tendrá asignada esa capacidad de memoria compartida, además dentro del kernel declaramos variables para manejar esa porción de memoria compartida utilizando los modificadores extern y __shared__.
Al igual que vimos anteriormente con la memoria local y con los registros, podemos consultar la cantidad de memoria compartida empleada en nuestro código con el modificador -Xptxas –v,abi=no. y en tiempo de ejecución utilizando la instrucción cuFuncGetAttribute(CU_FUNC_ATTRIBUTE_SHARED_SIZE_BYTES).
Consideraciones de rendimiento en el uso de memorias GPUs
Como ya nos podemos imaginar, la memoria va a jugar un papel clave en los algoritmos que implementemos en la GPU. Aunque la combinación del uso de las distintas memorias (registros, memoria compartida, textura, ...) nos va a permitir reducir el número de accesos a la GPU, tenemos que tener cuidadode no excedernos tampoco en el uso de estas memorias, ya que también van a producir una reducción de la ocupación de los procesadores de nuestra GPU. Es decir, cada dispositivo CUDA ofrece una cantidad limitada de memoria CUDA, la cual nos va limitar el número máximo de bloques e hilos que pueden estar ejecutándose de forma simultánea en los SMs. Por ejemplo, en la reciente NVIDIA GTX 1080, cada multiprocesador (SM) dispone de las siguientes características:
- 128 cores y 64K de registros
- 96 KB de memoria compartida
- 48 KB cache L1
- 16 KB cache para constantes
- hasta 2048 hilos por SM
Si tomamos como ejemplo el número de registros, nos damos cuenta de que cada hilo solo puede utilizar un número reducido de ese total de aproximadamente 64000 registros. Dado que para ocupar la capacidad de cómputo total de cada SM deberíamos ejecutar 2048 hilos a la vez, y que cada SM dispone de un máximo de 64000 registros, nos da alrededor un máximo de 30 registros por hilo. Si nuestros hilos necesitan utilizar más registros provocará que la capacidad de cómputo del SM no se utilice completamente y por lo tanto estemos no aprovechándo todo el potencial de cómputo. Algo similar ocurre con la memoria compartida, de la cual solo disponemos un cantidad limitada por SM y si intentamos utilizar más memoria compartida acabaremos infrautilizando la capacidad de cómputo de la GPU. Por ello, será necesario hacer un uso equilibrado de las diferentes memorias en la GPU para maximizar el rendimiento de nuestra aplicación.
Exprimiendo el ancho de banda de la memoria global
El acceso a la memoria global es uno de los principales causantes de degradamiento del rendimiento de una aplicación en la GPU. Debido a que normalmente las aplicaciones CUDA requieren procesar datos de forma masiva, es normal que se requiera acceder a grandes cantidades de información de la memoria global. Por ello, como ya hemos discutido haremos uso de la memoria de compartida y de los registros para aliviar estas latencias. Sin embargo, todavía es necesario mover esos datos desde memoria global a estas memorias más rápida y por lo tanto este movimiento de datos debe hacerse de la forma más eficiente posible.
La memoria global se encuentra implementada normalmente en memorias DRAMs (Dynamic Random Access Memory). La lectura de este tipo de memorias se lleva a cabo por líneas, de forma que cuando se lee un dato, también se leen las posiciones contiguas al dato que hemos leido. Teniendo en cuenta esta consideración, si queremos obtener el máximo rendimiento a la hora mover datos de la memoria global a otras memorias, será necesario implementar un acceso coalescente a memoria. Un acceso coalescente significa que hilos de ejecución accederán a posiciones contiguas de memoria en el mismo instante de tiempo, de forma que mediante una única lectura de memoria global podemos alimentar varios hilos en ejecución. A continuación podemos ver un ejemplo gráfico de accesos coalescentes y un kernel que implementa uno de las situaciones:

Ejemplo de kernel acceso coalescente a memoria global
__global__ coalesced_access(float*x)
{
int tid= threadIdx.x+ blockDim.x*blockIdx.x;
x[tid] = threadIdx.x;
}
Ejemplo de kernel acceso no coalescente a memoria global
__global__ not_coalesced_access(float*x)
{
int tid= threadIdx.x+ blockDim.x*blockIdx.x;
x[tid*100] = threadIdx.x;
}
La única forma de conseguir el máximo ancho de banda a la hora de transferir datos entre memoria global y otras memorias será mediante la correcta utilizando de patrones de acceso coalescente a memoria global, en caso contrario, estaremos limitando nuestra aplicación y no conseguiremos obtener un rendimiento máximo en la transferencia de datos.