Inicios y Evolución
Desde la aparición de la CPU, y por ello básicamente de los computadores de consumo, el rendimiento de los mismos ha seguido una progresión ascendente gracias principalmente a dos factores: el incremento de la velocidad de reloj y la capacidad de integrar más transistores de dimensiones y costes cada vez más reducidos. Prueba de este hecho es la archiconocida Ley de Moore, la cual básicamente establece que, aproximadamente cada dos años, se duplica el número de transistores integrados en un microprocesador tal y como se muestra en la Figura 1.
 Figura 1. Número de transistores en la CPU frente a la fecha de introducción de las mismas. La escala logarítimca en el eje vertical refleja el crecimiento exponencial de la capacidad de integración. Figura extraída de Wikipedia.
Figura 1. Número de transistores en la CPU frente a la fecha de introducción de las mismas. La escala logarítimca en el eje vertical refleja el crecimiento exponencial de la capacidad de integración. Figura extraída de Wikipedia.
Sin embargo, aunque estos métodos de incremento de rendimiento en la CPU han funcionado durante una gran cantidad de años, nos acercamos a límites fundamentales que impiden seguir creciendo en esta dirección: por una parte el consumo energético y el calor generado al aumentar la velocidad de reloj incrementa exponencialmente por lo que ir más allá no es una opción viable actualmente, por otro lado nos acercamos rápidamente al límite fisico en los tamaños de los transistores (puesto que por debajo de los 7 nanómetros se produce un fenómeno conocido como efecto túnel, impidiendo el correcto funcionamiento de los mismos). Así pues, los fabricantes de ordenadores de consumo comenzaron a prestar atención a los supercomputadores. Los supercomputadores también se han nutrido de los incrementos en la velocidad de reloj y en la integración de transistores para mejorar su rendimiento, pero los saltos masivos de rendimiento conseguidos se deben a otro hecho: el incremento en el número de procesadores trabajando en paralelo y en perfecta sincronización. Esto dio lugar a una revolución propia en los ordenadores de consumo, que comenzaron a incorporar más núcleos de procesamiento en las CPUs para poder seguir aumentando el rendimiento sin necesidad de incrementar las velocidades de reloj y por lo tanto sin sufrir problemas significativos de consumo energético o calor.
De forma resumida, esa es la evolución que han seguido las CPUs hasta la actualidad, sin embargo, en paralelo se produjo otra revolución en lo que respecta al procesamiento gráfico. A finales de los 80 y principios de los 90, los sistemas operativos con entorno gráfico supusieron una revolución de tal magnitud en los ordenadores de consumo que dieron lugar a la aparición de un nuevo mercado: los dispositivos aceleradores de gráficos 2D. A la vez, la compañía Silicon Graphics popularizó el uso de gráficos tridimensionales, llegando a su cumbre con la liberación de su librería e interfaz de programación OpenGL al público. Para mediados de los años 90, la demanda de aplicaciones que emplearan gráficos 3D creció motivada principalmente por la producción de videojuegos con una capacidad de inmersión nunca vista hasta la fecha. El impacto fue tan grande que se desencadenó una carrera por lograr entornos 3D cada vez más realistas tanto en videojuegos, animaciones o visualiazaciones de datos. Esta carrera puso de manifiesto la necesidad de una nueva tecnología: dispositivos aceleradores de gráficos tridimensionales suficientmente asequibles como para conseguir un hueco en el mercado de computadores de consumo. El lanzamiento de la NVIDIA GeForce 256 marcó un antes y un después, al implementar en el propio hardware una gran parte de la funcionalidad del pipeline gráfico (mostrado en la Figura 2) utilizado en OpenGL, desbloqueando la capacidad de producir aplicaciones con una fidelidad gráfica sin precedentes para aquél momento.
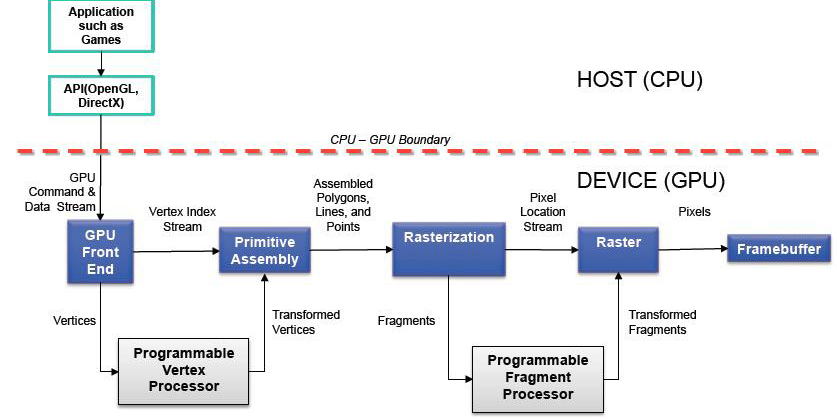
Figura 2. El pipeline gráfico.
La Unidad de Procesamiento Gráfico (GPU)
El término Graphics Processing Unit (GPU) fue introducido por primera vez por NVIDIA al lanzar al mercado su primera familia de productos GeForce: la GeForce 256 como sucesora de la tarjeta RIVA TNT2. Esta tarjeta fue definida por la propia empresa como "The first Graphics Processing Unit: A single-chip processor with integrated transform, lighting, triangle setup\/clipping, and rendering engines that is capable of processing a minimum of 10 million polygons per second."
Así pues, desde este momento el término GPU, desde un punto de vista funcional, se utilizaría para referirse a aquél dispositivo concebido para la aceleración del proceso de renderizado de datos 3D en imágenes 2D y depositarlas en un framebuffer para su posterior visualización, con todo lo que ello conlleva, es decir, la aceleración de todo tipo de operaciones gráficas: operaciones geométricas sobre vértices, ensamblaje y renderizado de polígonos, mapeado de texturas, rasterización, reproducción y codificación de vídeo entre otros. Estas operaciones se caracterizan por ser de naturaleza intrínsecamente puesto que sus elementos pueden ser procesados de forma independiente. La GPU es un procesador capaz de explotar este paralelismo y por lo tanto obtener un rendimiento mucho mayor para este tipo de operaciones que una CPU secuencial convencional.
Desde un punto de vista arquitectural en un computador de consumo, la GPU es una tarjeta de expansión que actualmente se conecta al resto del sistema mediante puertos PCI Express (PCIe). Cabe destacar el que es probablemente el elemento de mayor importancia en un computador: el chipset, cuya función es la de gestionar las conexiones de la CPU con todo el resto de componentes. En los sistemas actuales, este chipset se divide en dos componentes: southbridge y northbridge. El primero de ellos conecta la mayoría de los periféricos al sistema mientras que el segundo gestiona los buses de gráficos (actualmente PCIe) y la comunicación con la memoria principal de la CPU (mediante el front-side bus). La Figura 3 muestra un esquema típico de un sistema CPU\/GPU conectada mediante un puerto PCIe.
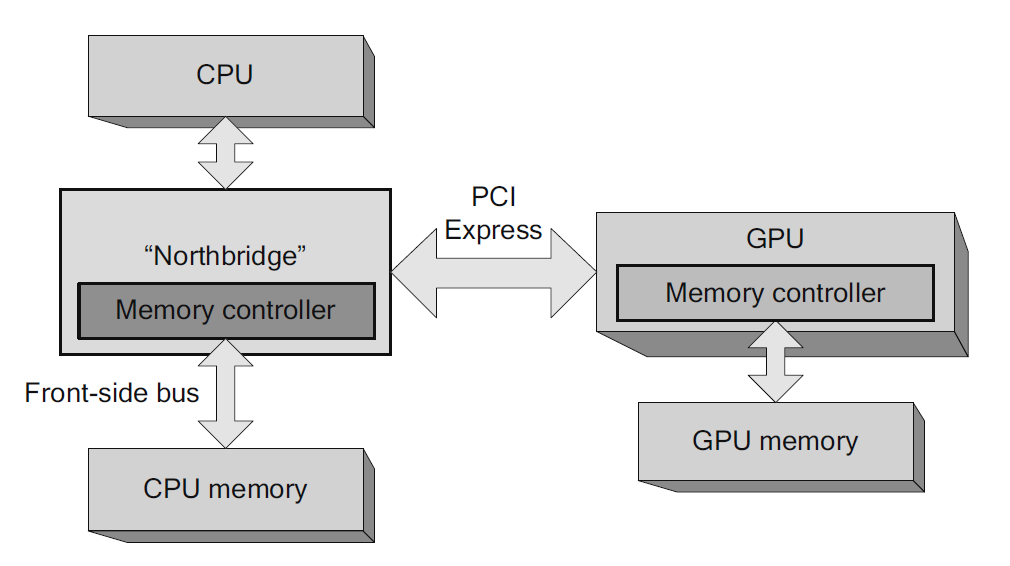
Figura 3. Arquitectura CPU\/GPU típica (nótese que el southbridge del chipset ha sido omitido por simplicidad). Figura extraída de "The CUDA Handbook: A Comprehensive Guide to GPU Programming".
Existen configuraciones alternativas en los computadores de consumo como pueden ser las GPUs integradas en el propio chipset de forma que el propio northbridge las alberga y comparten tanto controlador de memoria como la propia memoria física con la CPU. Este tipo de configuración se muestra en la Figura 4.
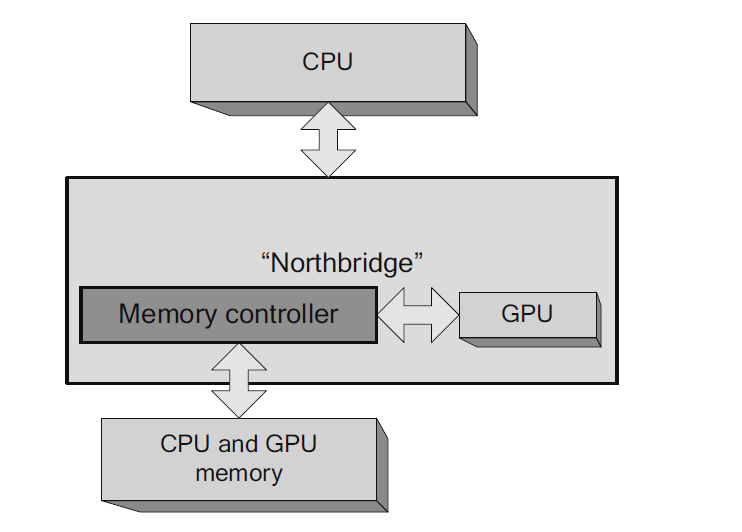
Figura 4. Arquitectura CPU\/GPU integrada. Figura extraída de "The CUDA Handbook: A Comprehensive Guide to GPU Programming".
Otra de las configuraciones alternativas, aunque quizás menos común, es la de múltiples GPUs en diferentes puertos PCIe e incluso múltiples GPUs en la misma tarjeta empleando un puente para evitar la comunicación por el propio puerto PCIe. Una alternativa a este último caso consiste en emplear las tecnologías Scalable Link Interface (SLI) en tarjetas NVIDIA o CrossFire en placas AMD para hacer que múltiples GPUs se comporten como una más potente. De cualquier manera, cada GPU posee su propio espacio y controlador de memoria, simplemente las GPUs conectadas pueden emplear el puente (ya sea integrado en el chip o en forma de conector SLI o CrossFire) para evitar el puerto PCIe a la hora de realizar comunicaciones entre ellas. Este tipo de configuración multi-GPU se muestra en la Figura 5.
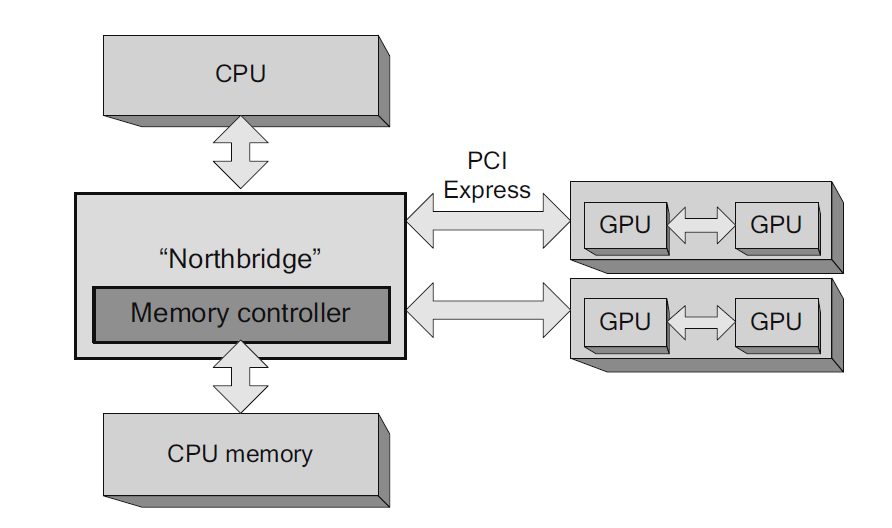
Figura 5. Arquitectura CPU\/multi-GPU. Figura extraída de "The CUDA Handbook: A Comprehensive Guide to GPU Programming".
Primeros Pasos en Computación sobre GPUs
La llegada de la serie GeForce 3 de NVIDIA en el año 2001 supuso otra revolución en lo que respecta a tecnologías de procesamiento gráfico pues no solamente todo el pipeline gráfico era ejecutado en un procesador, sino que además las etapas de vertex y pixel shading eran programables. Esto permitió a los propoios desarrolladores tener un control sobre los cómputos realizados en la GPU, pudiendo conseguir efectos de mucha mayor fidelidad. A la vez, esta programabilidad atrajo el interés de múltiples investigadores que vieron la oportunidad de reaprovechar la gran capacidad para realizar cómputos paralelos de las GPUs con otro fin que el renderizado de gráficos empleando OpenGL o DirectX.
Esencialmente, los primeros pasos consistieron en reemplazar los datos de entrada gráficos esperados por las etapas programables (shaders) por datos numéricos, y a su vez reprogramar los shaders para realizar cualquier tipo de cómputo paralelo arbitrario sobre dichos datos. Los resultados, aparentemente gráficos, producidos por la GPU simplemente eran recuperados e interpretados de forma distinta. En definitiva, la GPU estaba siendo "engañada" realizando cómputos de propósito general haciéndolos parecer como si se trataran de operaciones de renderizado. Gracias a la gran capacidad de cómputo que poseían las GPUs del momento para realizar operaciones aritméticas enteras en paralelo, los resultados iniciales fueron prometedores en cuanto al rendimiento y aceleración que se podía conseguir en aplicaciones sencillas. Este paradigma consistente en emplear los recursos de la GPU para realizar cómputos no gráficos fue denominado General Purpose computation on Graphics Processing Units (GPGPU).
No obstante, existían múltiples limitaciones de diversa naturaleza que dificultaron en gran medida la adopción de este paradigma de computación de propósito general sobre GPUs al público desarrollador general:
- La única forma de interactuar con la GPU para realizar los cómputos era mediante DirectX u OpenGL por lo que los desarroladores debían aprender y dominar sus APIs, con el esfuerzo de "traducción" que conllevaba modificar un programa existente para expresarlo como cómputos gráficos y engañar a la GPU.
- Además, esta dificultad no se limitaba únicamente a la estructura y flujo general del programa, sino que las propias operaciones que iban a ser paralelizadas debían ser escritas en lenguajes propios de gráficos para los shaders como Cg o GLSL. Estos dos factores suponían una curva de aprendizaje demasiado elevada para la adopción general.
- El soporte para operaciones en en coma flotante (float o double) no estaba garantizado por lo que muchas aplicaciones científicas no podían ser ejecutadas en una GPU.
- Las operaciones de escritura de memoria poseían serias limitaciones, por ejemplo, aquellos programas que necesitaban patrones del tipo scatter (escrituras en posiciones arbitrarias) no podían ser ejecutados.
- No existían métodos de depuración ni de control de errores, por lo que si el programa tenía un fallo podía ocurrir un amplio abanico de situaciones: resultados incorrectos, fallos al terminar e incluso cuelgues.
- Los recursos eran limitados en todos los sentidos: escasa memoria, tipos de datos limitados, poca flexibilidad en las operaciones...
La Arquitectura CUDA
Como respuesta a las limitaciones existentes y a la exigente curva de aprendizaje impuesta por las APIs gráficas, NVIDIA presentó una nueva tarjeta gráfica revolucionaria y que daría el pistoletazo de salida a la madurez del campo de la computación sobre GPUs: la GeForce 8800 GTX. Esta tarjeta sería la primera GPU en ser diseñada con la arquitectura NVIDIA Compute Unified Device Architecture (CUDA).
Desde el punto de vista de hardware, la arquitectura CUDA solventó las principales limitaciones hasta la fecha:
- Anteriormente los recursos físicos de la GPU estaban particionados en shaders de vértices y de píxeles, con la introducción de CUDA se incluyeron los llamados shaders unificados. De esta forma cualquier unidad computacional de la tarjeta puede utilizarse para cualquier tarea programable, consiguiendo un balanceo de carga mucho más efectivo y evitando las dificultades impuestas por la distinción anterior.
- Todas las Unidades Aritmético Lógicas (ALUs) de estas unidades de cómputo fueron construidas para soportar los estándares del IEEE para operaciones aritméticas en punto flotante de precisión simple (float), por lo que se abrió la puerta a un amplio rango de aplicaciones científicas.
- Por otra parte, los patrones de acceso y escritura a memoria se flexibilizaron de forma que las unidades de ejecución fueran capaces de realizar lecturas y escrituras arbitrarias e incluso acceder a una memoria caché de mayor velocidad llamada memoria compartida. Esto provocó que, por ejemplo, aplicaciones que requirieran el uso de patrones como scatter pudieran ser implementadas y ejecutadas en una GPU.
Sin embargo, el cambio más notable no ocurrió solamente en el hardware. De nada hubieran servido todos los avances antes mencionados si las dificultades para los desarrolladores, en forma de la necesitad de utilizar OpenGL o DirectX para acceder a los recursos de la GPU y los lenguajes de shading para expresar los cómputos, hubieran continuado. En este sentido, la arquitectura CUDA va más allá de un mero avance de hardware, es un ecosistema completo que incluye un lenguaje propio para programar las GPUs compatibles (CUDA C\/C++), un compilador de dicho lenguaje a instrucciones comprensibles por la GPU (NVCC) y un driver especializado para explotar toda la capacidad de cómputo de la GPU.
Gracias a la eliminación de las barreras hardware y software, se dio rienda suelta a un paradigma que ha cobrado tanta importancia en la actualidad que ha supuesto, entre otras cosas, una revolución total en la forma de entender la computación.